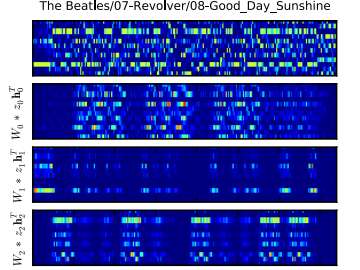
A probabilistic latent component analysis of a pitch class sequence for The Beatles’ Good Day Sunshine. The top layer shows the original representation (time vs pitch class). Subsequent layers show latent components.
What is music? Or rather, what differentiates music from noise?
If you ask John Cage, “everything we do is music.” Forced to sit silently for 4’33”, we masters of apophenia end up hearing music in noise (or just squirm in discomfort…), perceiving order and meaning in sounds that normally escape notice. For Cage, music is in the ears of the listener. To study it is to study how we perceive.
But Cage wrote 4’33” at time when many artists were challenging inherited notions of art. Others, dating back to Pythagoras (who defined harmony in terms of ratios and proportions), have defined music through the structural properties that make music music, and separate different musical styles.
The latest efforts to understand music lie in the field of machine listening, where researchers use computers to analyze audio data to identify meaning and structure in it like humans do. Some machine listening researchers analyze urban and environmental sounds, as at SONYC.
This August in NYC, researchers in machine listening and related fields will convene at the International Society for Music Information Retrieval (ISMIR) conference. The conference is of interest to anyone working in data or digital media, offering practical workshops and hackathons for the NYC data community.
We interviewed NYU Steinhardt Professor Juan Pablo Bello, an organizer of ISMIR 2016 working in machine listening, to learn more about the conference and the latest developments in the field. Keep reading for highlights!